本文将分析Hadoop MapReduce(包括MRv1和MRv2)的两种常见的容错场景,第一种是,作业的某个任务阻塞了,长时间占用资源不释放,如何处理?另外一种是,作 业的Map Task全部运行完成后,在Reduce Task运行过程中,某个Map Task所在节点挂了,或者某个Map Task结果存放磁盘损坏了,该如何处理?
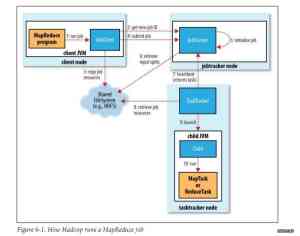
第一种场景:作业的某个任务阻塞了,长时间占用资源不释放,如何处理?
这种场景通常是由于软件Bug、数据特殊性等原因导致的,会让程序阻塞,任务运行停滞不前。在外界看来,任务(Task)好像阻塞了一样。这种事情 经常发生,由于任务长时间占用着资源但不使用(如果不采取一定的手段,可能永远不会被使用,造成“资源泄露”),会导致资源利用率下降,对系统不利,那 么,Hadoop MapReduce遇到这种情况如何处理呢?
在TaskTracker上,每个任务会定期向TaskTracker汇报新的进度(如果进度不变则不汇报),并由TaskTracker进一步汇 报给JobTracker。当某个任务被阻塞时,它的进度将停滞不前,此时任务不会向TaskTracker汇报进度,这样,一定达到超时时间上 限,TaskTracker会将该任务杀掉,并将任务状态(KILLED)汇报给JobTracker,进而触发JobTracker重新调度该任务。
在实际应用场景中,有些正常的作业,其任务可能长时间没有读入或者输出,比如读取数据库的Map Task或者需要连接其他外部系统的Task,对于这类应用,在编写Mapper或Reducer时,应当启动一个额外的线程通过Reporter组件定 期向TaskTracker汇报心跳(只是告诉TaskTracker自己还活着,不要把我杀了)。
第二种场景:作业的Map Task全部运行完成后,在Reduce Task运行过程中,某个Map Task所在节点挂了,或者Map结果存放磁盘损坏了,该如何处理?
这种场景比较复杂,需分开讨论。
如果节点挂了,JobTracker通过心跳机制知道TaskTracker死掉了,会重新调度之前正在运行的Task和正在运行的作业中已经运行完成的Map Task。
如果节点没有挂,只是存放Map Task结果的磁盘损坏了,则分两种情况:
(1)所有的Reduce Task已经完成shuffle阶段
(2)尚有部分Reduce Task没有完成shuffle阶段,需要读取该Map Task任务
对于第一种情况,如果所有Reduce Task一路顺风地运行下去,则无需对已经运行完成的Map Task作任何处理,如果某些Reduce Task一段时间后运行失败了,则处理方式与第二种一样。
对于第二种情况,当Reduce Task远程读取那个已经运行完成的Map Task结果(但结果已经损坏)时,会尝试读取若干次,如果尝试次数超过了某个上限值,则会通过RPC告诉所在的TaskTracker该Map Task结果已经损坏,而TaskTracker则进一步通过RPC告诉JobTracker,JobTracker收到该消息后,会重新调度该Map Task,进而重新计算生成结果。
需要强调的是,目前Hadoop MapReduce的实现中,Reduce Task重试读取Map Task结果的时间间隔是指数形式递增的,计算公式是10000*1.3^noFailedFetches,其中noFailedFetches取值范围 为MAX{10, numMaps/30},也就是说,如果map task数目是300,则需要尝试10次才会发现Map Task结果已经损坏,尝试时间间隔分别是10s,13s,21s,28s,37s,48s,62s,81s和106s,需要非常长的时间才能发现,而且 Map Task越多,发现时间越慢,这个地方通常需要调优,因为任务数目越多的作业,越容易出现这种问题。
在MapReduce V2.0中,所有任务(Map Task和Reduce Task)直接跟MRAppMaster交互,不需要通过类似于TaskTracker这样的中间层,整个过程与上述过程类似,在此不再赘述,具体可阅读书籍《Hadoop技术内幕:深入解析YARN架构设计与实现原理》中的“第8章 离线计算框架MapReduce”。
在mapreduce中设计了Speculator接口作为推断执行的统一规范,DefaultSpeculator作为一种服务在实现了Speculator的同时继承了AbstractService,DefaultSpeculator是mapreduce的默认实现。
据测试结果得知,在使用了206个EC2节点的情况下,Spark将排序用时缩短到了23分钟。这意味着在使用十分之一计算资源的情况下,相同数据的排序上,Spark比MapReduce快3倍!
这篇文章将介绍基于物品的协同过滤推荐算法案例在TDWSpark与MapReudce上的实现对比,相比于MapReduce,TDWSpark执行时间减少了66%,计算成本降低了40%。
过去两年,Hadoop社区对MapReduce做了很多改进,但关键的改进只停留在了代码层,Spark作为MapReduce的替代品,发展很快,其拥有来自25个国家超过一百个贡献者,社区非常活跃,未来可能取代MapReduce。
在Mapreduce 的程序设计中,有时候会遇到多文件输出的使用,目前总结为两种方法:第一种方法:使用MultipleOutputFormat,第二种方式:使用MultipleOutputs。
【聚焦搜索,数智采购】2021第一届百度爱采购数智大会即将于5月28日在上海盛大开启!
本次大会上,紫晶存储董事、总经理钟国裕作为公司代表,与中国―东盟信息港签署合作协议
XEUS统一存储已成功承载宣武医院PACS系统近5年的历史数据迁移,为支持各业务科室蓬勃扩张的数据增量和访问、调用乃至分析需求奠定了坚实基础。
大兆科技全方面展示大兆科技在医疗信息化建设中数据存储系统方面取得的成就。
双方相信,通过本次合作,能够使双方进一步提升技术实力、提升产品品质及服务质量,为客户创造更大价值。










